

MaskGCT TTS: The Open Source Breakthrough in Text-to-Speech Technology
MaskGCT TTS has emerged as a revolutionary player in the text-to-speech (TTS) arena, delivering unprecedented innovation in both design and usability. Unlike traditional TTS models, MaskGCT operates as a non-autoregressive model that eliminates the need for text-speech alignment, making it both faster and more efficient. Built on open-source principles, MaskGCT paves the way for adaptable, high-quality voice synthesis that's set to redefine voice applications across industries. In this article, we dive into MaskGCT's unique architecture, innovation, and its powerful applications for developers and content creators.
Also read: F5TTS: Free AI Voice Model for High-Quality Text-to-Speech
What Sets MaskGCT TTS Apart in Text-to-Speech?
MaskGCT TTS stands out for its non-autoregressive design, which reduces dependency on supervised alignment between text and speech. This breakthrough results in smoother, faster voice generation without the traditional lag or quality drop-offs found in autoregressive models. By allowing zero-shot voice generation, MaskGCT opens up extensive possibilities for customizable and high-quality TTS.

MaskGCT TTS Architecture: A Closer Look
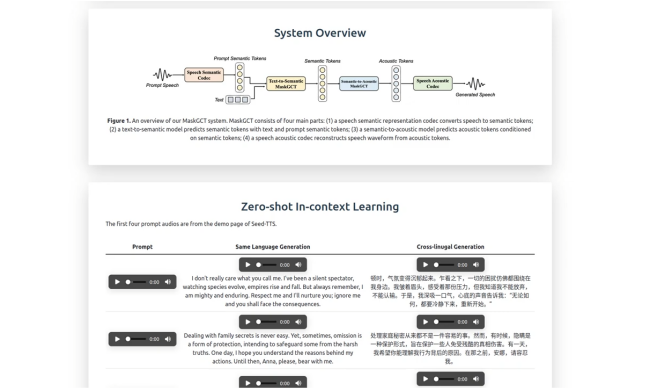
MaskGCT TTS uses an architecture designed for high-quality, natural-sounding speech synthesis, with elements focusing on efficient generation, customization, and real-time application. Here's a closer look at the architecture and its components:
- Non-Autoregressive Framework
MaskGCT leverages a non-autoregressive framework that diverges from the traditional TTS models by removing the need for frame-by-frame alignment. This advancement not only reduces latency but also enables smoother, more human-like speech synthesis.
- Core Components and Innovations
The architecture of MaskGCT integrates high-level AI components such as Transformers, which help in capturing contextual nuances, and it uses advanced data processing pipelines to deliver high-resolution audio output. By integrating the open-source Emilia dataset, MaskGCT optimizes its model training on diverse language and voice data, making it versatile for various applications.
How to Use MaskGCT TTS in Your Projects
MaskGCT TTS (Text-to-Speech) is a tool for generating lifelike, customizable voice output, making it popular in fields like virtual assistants, gaming, and content creation. Here's a step-by-step guide on how to integrate and use MaskGCT TTS in your projects:
1. Setup and Integration: One of the main attractions of MaskGCT TTS is its open-source availability, which makes it accessible to developers aiming to integrate TTS into their own platforms. The setup process involves downloading the model from its repository and linking it with compatible software. It's a flexible solution that allows for modification to meet specific project needs.
2. Integrate API in Your Code: Import MaskGCT's SDK or use HTTP requests to interact with the API. Send the text you want to convert to speech along with customization parameters like voice type, pitch, and speed.
3. Process and Play the Audio Output: Save the audio response (e.g., MP3 or WAV) locally or stream it directly in your application. Use audio libraries or the built-in media functions in your application's environment to play or manage the generated audio.
Key Use Case for MaskGCT TTS
MaskGCT's applications are vast, from content creation to voice assistants. Its ability to handle high-quality, zero-shot voice output makes it ideal for personalized audio generation, virtual assistants, and other applications where unique, realistic voice synthesis is key. Here are some key use cases for MaskGCT TTS:
1. Enhanced Naturalness and Expressivity: MaskGCT can generate expressive, nuanced voices that mimic natural human inflections, suitable for customer service scenarios requiring empathy and adaptability.
2. Accent and Dialect Adaptation: MaskGCT's capabilities in accent adaptation make it a valuable tool for language learning applications, offering users a more natural experience with diverse accents and dialects.
3. Dynamic and Real-Time Applications: MaskGCT can be used in gaming to dynamically generate voices for non-playable characters (NPCs) or provide live commentary, creating a more immersive experience.
Why MaskGCT TTS is the Open Source Breakthrough We've Been Waiting For?
With its efficient non-autoregressive model, customizable open-source access, and user-friendly integration, MaskGCT TTS is reshaping expectations for TTS capabilities. Its innovation offers endless possibilities for developers and content creators, pushing the boundaries of how synthetic voices are used in real-world applications.
Conclusion
MaskGCT TTS exemplifies what's possible when open-source innovation meets practical application. As it continues to evolve, this TTS model promises to transform voice technology across industries, making high-quality, realistic voice synthesis more accessible than ever.