

How to Set Up Kokoro Text-to-Speech Model Locally
Text-to-Speech (TTS) technology has made huge strides in recent years, allowing users to convert written text into speech. Free and dependable TTS model is key for you to greatly improve accessibility and efficiency, such as F5TTS and XTTS-WebUI. In this guide, we will show you how to set up Kokoro Text-to-Speech model locally on your computer. It's completely free, and you won't need a high-end GPU to get started. Let's dive into the process and you can start using this powerful TTS tool without relying on costly, cloud-based services.

Why Choose Kokoro Text-to-Speech Model?
When considering a Text-to-Speech solution, choosing a free, open-source model offers several benefits. You can completely control over your setup and avoid the ongoing costs associated with cloud-based TTS services. The open-source nature of these models means that anyone can access, modify, and improve them. Moreover, running the model locally keeps your privacy and faster the processing speeds, as you won't need to upload your data to the internet.
Benefits of Using Kokoro Text-to-Speech Model
Running this TTS model locally offers several advantages:
- No Internet Required: The model works without needing an internet connection after setup.
- Full Control: Customize the voice and settings to fit your needs.
- Free of Charge: Save money by using a free, open-source solution.
- Privacy: Your data stays on your computer keeping it totally private.
Install Your Free Open-Source Text-to-Speech Model Locally
Getting started with Kokoro Text-to-Speech model requires several simple steps. Below, we walk you through setting up an 82 million-parameter open-source TTS model on your local machine.
Step 1: Install Required Dependencies
Before you begin, make sure you have the necessary dependencies installed. This includes Git LFS for cloning the repository and other libraries like PyTorch for model processing. You also need a speech synthesizing engine like esak NG for generating the audio.
- Git LFS: This tool is essential for handling large files and you can clone the repository without downloading the huge model files initially.
- PyTorch: A powerful library for deep learning that makes the TTS model to run efficiently on your machine.
- esak NG: This engine handles the speech synthesis, converting text into speech.
Step 2: Clone the Repository
When dependencies are installed, the next step is to clone the open-source Text-to-Speech model repository. By cloning the repository, you'll gain access to the model files and configuration settings required to run the model in a local environment. Make sure to skip the large model files during the clone process; these can be downloaded later.
How to Configure the TTS Model for Your System
After cloning the repository and installing all the necessary libraries, you'll need to configure the TTS model. This includes setting the device to either a CPU or GPU and selecting the voice pack you want to use.
Configuring the Device for Text-to-Speech
If you are using a machine with a GPU, you can enable CUDA support to speed up the TTS process. For those on Mac or with an AMD processor, the model will default to CPU, but CUDA is the preferred option for faster processing.
Downloading the Model Files and Voice Packs
Once everything is set up, you'll need to download the model files and voice packs. These are the core components that make your TTS model to generate speech from text. The model files are around 350MB, and voice packs can vary in size depending on the voice type.
Downloading the Model
Use commands to download the model file and ensure that the voice pack is compatible with the voice you want to use. For instance, you could choose an American female voice similar to OpenAI's Sky.
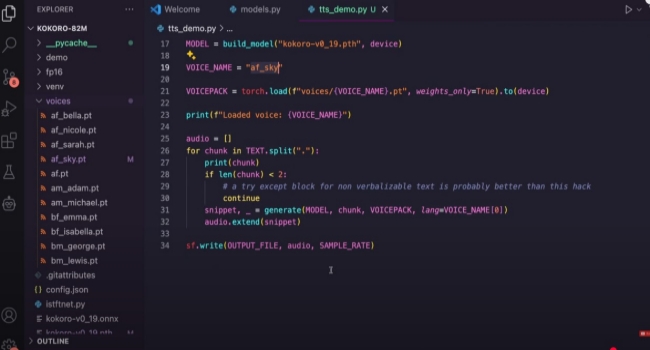
Running the Text-to-Speech Model Locally
After configuring everything and the files are downloaded, you can run the model. The Python script will convert your input text into speech, saving the output as a .wav file. With the model running locally, you can generate speech as needed, without relying on internet-based services.
Verifying Your Setup
Once you run the model, check the output file to confirm that the text has been successfully converted into speech. You can adjust the speed, pitch, or volume of the speech if needed, making this a highly customizable solution.
Conclusion
Kokoro is an open-source, customizable assistance that gives you complete control over your speech generation. If you are a developer, content creator, or someone looking for an online TTS service, SeaArt AI Audio is a professional tool to generate audio. Or if you are desiring for a local TTS setup guide, this guide has shown you the step-by-step process to get started.